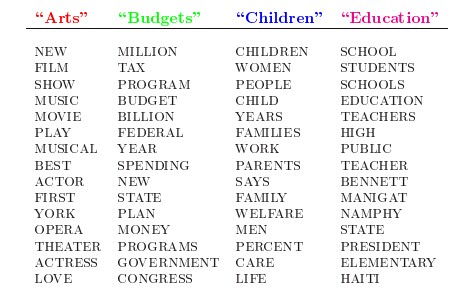
人类是怎么生成文档的呢?LDA的这三位作者在原始论文中给了一个简单的例子。比如假设事先给定了这几个主题:Arts、Budgets、Children、Education,然后通过学习训练,获取每个主题Topic对应的词语。如下图所示:
然后以一定的概率选取上述某个主题,再以一定的概率选取那个主题下的某个单词,不断的重复这两步,最终生成如下图所示的一篇文章(其中不同颜色的词语分别对应上图中不同主题下的词):

而当我们看到一篇文章后,往往喜欢推测这篇文章是如何生成的,我们可能会认为作者先确定这篇文章的几个主题,然后围绕这几个主题遣词造句,表达成文。
LDA就是要干这事: 根据给定的一篇文档,推测其主题分布。
通俗来说,可以假定认为 人类是根据上述文档生成过程写成了各种各样的文章,现在某小撮人想让计算机利用LDA干一件事:你计算机给我推测分析网络上各篇文章分别都写了些啥主题,且各篇文章中各个主题出现的概率大小(主题分布)是啥。
然,就是这么一个看似普通的LDA,一度吓退了不少想深入探究其内部原理的初学者。难在哪呢,难就难在LDA内部涉及到的数学知识点太多了。
在LDA模型中,一篇文档生成的方式如下:
- 从狄利克雷分布
中取样生成文档 i 的主题分布
- 从主题的多项式分布
中取样生成文档i第 j 个词的主题
- 从狄利克雷分布
中取样生成主题
对应的词语分布
- 从词语的多项式分布
中采样最终生成词语
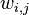
其中,类似Beta分布是二项式分布的共轭先验概率分布,而狄利克雷分布(Dirichlet分布)是多项式分布的共轭先验概率分布。
此外,LDA的图模型结构如下图所示: